
 Researcher at DeepSeek AI
|
Researcher at DeepSeek AI
|
 Ph.D. in AI, Peking University
Ph.D. in AI, Peking University
I am a Researcher at DeepSeek AI, where I post-train large language models to strengthen their agentic capabilities, with a focus on coding agents. My question: how can scalable training turn a language model into an agent that reliably plans, acts, and self-corrects on real-world software engineering tasks?
I am also interested in multimodal agents, such as GUI agents and agents in 3D game worlds. This interest stems from my doctoral research at Peking University on multi-task agents in open-world settings. As first author, I led the GROOT and ROCKET series, building agents that follow human instructions to complete intricate Minecraft tasks, emphasizing task representations that are expressive, low-ambiguity, and scalable for efficient training.
Education
-
Peking University Sep. 2022 - Jul. 2026SIST × IAI
Ph.D. · Computer Science & Technology -
 University of Chinese Academy of Sciences Sep. 2019 - Jul. 2022Institute of Computing Technology, Chinese Academy of Sciences
University of Chinese Academy of Sciences Sep. 2019 - Jul. 2022Institute of Computing Technology, Chinese Academy of Sciences
M.S. · Computer Technology -
 Xi'an Jiaotong University Sep. 2015 - Jul. 2019Software College
Xi'an Jiaotong University Sep. 2015 - Jul. 2019Software College
B.Eng. · Software Engineering
Experience
-
DeepSeek AI Oct. 2025 - nowDeep Learning Researcher · CodeMath Team
Honors & Awards
- Gold Medal · ACM-ICPC Asia Regional 2018
- Winner · ATEC 2025 Robotics & AI Challenge (Software) 2025
- Outstanding Graduate of Beijing 2026
- Outstanding Graduate of Peking University 2026
News
-
Excited to have contributed to DeepSeek V4 — now available as a preview release! 🎉Apr 24
-
Excited to have contributed to DeepSeek-V3.2 — now officially released with built-in reasoning for agents! 🎉Dec 01
-
Our work "ROCKET-2" has been accepted to AAAI 2026!Nov 08
-
Joined DeepSeek AI as a Researcher! 🎉Oct 28
-
Introducing "ROCKET-3", the first multi-task reinforcement learning agent in Minecraft — a fitting finale to the ROCKET series. 🎉Aug 01
-
Released "ROCKET-2", a state-of-the-art Minecraft agent with cross-view goal specification!Mar 05
-
Our work "ROCKET-1" has been accepted to CVPR 2025!Feb 28
-
Our work "GROOT-2" has been accepted to ICLR 2025!Jan 23

Selected Publications (view all )

Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Shaofei Cai*, Zhancun Mu*, Haiwen Xia, Bowei Zhang, Anji Liu, Yitao Liang (* equal contribution)
arxiv 2025
The first reinforcement learning trained multi-task policy in the Minecraft world, demonstrating zero-shot generalization capability to other 3D domains.
Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Shaofei Cai*, Zhancun Mu*, Haiwen Xia, Bowei Zhang, Anji Liu, Yitao Liang (* equal contribution)
arxiv 2025
The first reinforcement learning trained multi-task policy in the Minecraft world, demonstrating zero-shot generalization capability to other 3D domains.

ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Shaofei Cai, Zhancun Mu, Anji Liu, Yitao Liang
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI'26) 2025
We aim to develop a goal specification method that is semantically clear, spatially sensitive, and intuitive for human users to guide agent interactions in embodied environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their own camera views rather than the agent's observations.
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Shaofei Cai, Zhancun Mu, Anji Liu, Yitao Liang
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI'26) 2025
We aim to develop a goal specification method that is semantically clear, spatially sensitive, and intuitive for human users to guide agent interactions in embodied environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their own camera views rather than the agent's observations.
ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, Yitao Liang
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
We propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from past observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, supported by real-time object tracking from SAM-2.
ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
Shaofei Cai, Zihao Wang, Kewei Lian, Zhancun Mu, Xiaojian Ma, Anji Liu, Yitao Liang
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
We propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from past observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, supported by real-time object tracking from SAM-2.
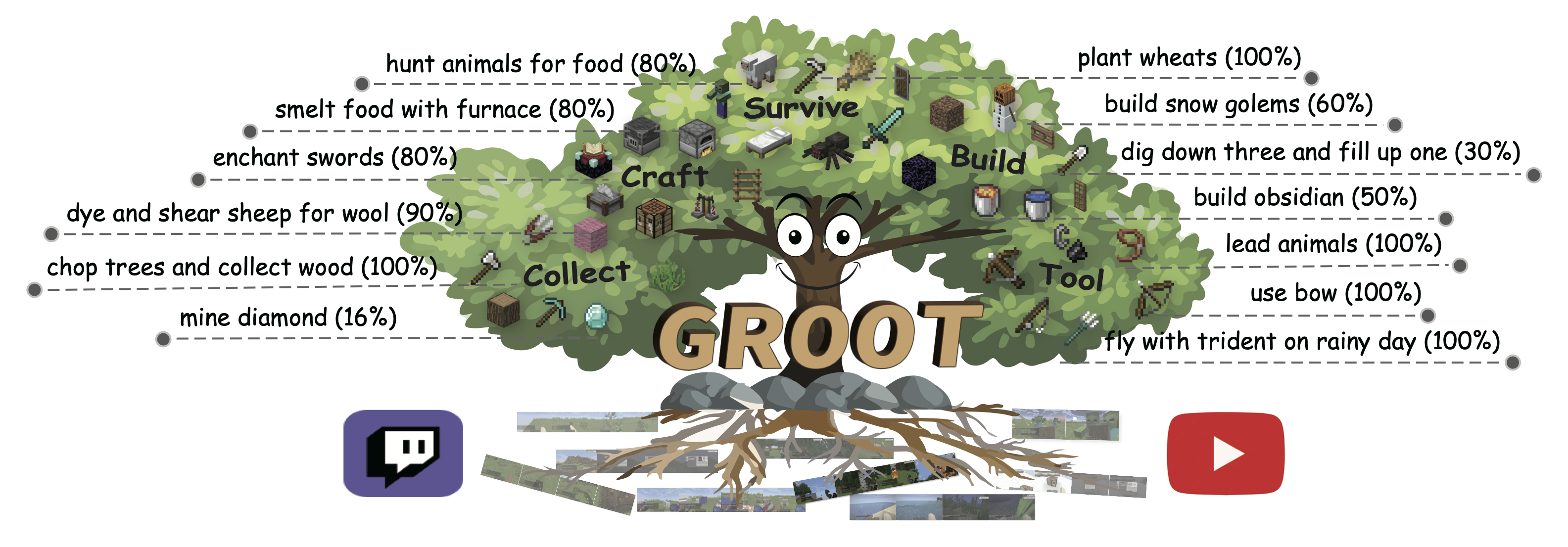
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
Shaofei Cai, Bowei Zhang, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
This paper studies the problem of building a controller that can follow open-ended instructions in open-world environments. We propose to follow reference videos as instructions, which offer expressive goal specifications while eliminating the need for expensive text-gameplay annotations. A new learning framework is derived to allow learning such instruction-following controllers from gameplay videos while producing a video instruction encoder that induces a structured goal space.
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
Shaofei Cai, Bowei Zhang, Zihao Wang, Xiaojian Ma, Anji Liu, Yitao Liang
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
This paper studies the problem of building a controller that can follow open-ended instructions in open-world environments. We propose to follow reference videos as instructions, which offer expressive goal specifications while eliminating the need for expensive text-gameplay annotations. A new learning framework is derived to allow learning such instruction-following controllers from gameplay videos while producing a video instruction encoder that induces a structured goal space.
Automatic Relation-aware Graph Network Proliferation
Shaofei Cai, Liang Li, Xinzhe Han, Jiebo Luo, Zhengjun Zha, Qingming Huang
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
This paper proposes Automatic Relation-aware Graph Network Proliferation (ARGNP) for efficiently searching GNNs with a relation-guided message passing mechanism. Specifically, we first devise a novel dual relation-aware graph search space that comprises both node and relation learning operations. These operations can extract hierarchical node/relational information and provide anisotropic guidance for message passing on a graph. Second, analogous to cell proliferation, we design a network proliferation search paradigm to progressively determine the GNN architectures by iteratively performing network division and differentiation.
Automatic Relation-aware Graph Network Proliferation
Shaofei Cai, Liang Li, Xinzhe Han, Jiebo Luo, Zhengjun Zha, Qingming Huang
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
This paper proposes Automatic Relation-aware Graph Network Proliferation (ARGNP) for efficiently searching GNNs with a relation-guided message passing mechanism. Specifically, we first devise a novel dual relation-aware graph search space that comprises both node and relation learning operations. These operations can extract hierarchical node/relational information and provide anisotropic guidance for message passing on a graph. Second, analogous to cell proliferation, we design a network proliferation search paradigm to progressively determine the GNN architectures by iteratively performing network division and differentiation.