
 DeepSeek AI · 深度学习研究员
|
DeepSeek AI · 深度学习研究员
|
 北京大学 · 人工智能博士
北京大学 · 人工智能博士
我目前是 DeepSeek AI 的深度学习研究员,主要从事大语言模型的后训练以增强其智能体能力,重点方向是代码智能体。 我关心的问题是:如何通过可扩展的训练,让语言模型成长为一个在解决真实软件工程任务时能够稳定地规划、执行并自我纠错的智能体。
我同样对多模态智能体抱有浓厚的兴趣,例如 GUI 智能体,以及 3D 游戏世界中的智能体。 这份兴趣源自我在北京大学的博士研究:我围绕开放世界环境中的多任务智能体展开工作,作为第一作者主导了 GROOT 与 ROCKET 系列,让 AI 智能体能够遵循人类指令、在《我的世界》游戏中完成复杂任务,持续推动 3D 游戏环境中智能体能力的前沿。 其中一个核心主题是寻找兼具高表达力、低歧义、且可扩展用于高效训练的任务表征。
教育经历
-
北京大学 2022.09 - 2026.07智能学院 × 人工智能研究院
博士 · 计算机科学与技术(智能科学与技术) -
 中国科学院大学 2019.09 - 2022.07中国科学院计算技术研究所
中国科学院大学 2019.09 - 2022.07中国科学院计算技术研究所
硕士 · 计算机技术 -
 西安交通大学 2015.09 - 2019.07软件学院
西安交通大学 2015.09 - 2019.07软件学院
学士 · 计算机软件工程
工作经历
-
DeepSeek AI 2025.10 - 至今深度学习研究员 · CodeMath 团队
荣誉与奖项
- 金牌 · ACM-ICPC 国际大学生程序设计竞赛亚洲区域赛 2018
- 冠军 · ATEC 2025 机器人与人工智能挑战赛 · 软件赛道 2025
- 北京市普通高等学校优秀毕业生 2026
- 北京大学优秀毕业生 2026
动态
-
很高兴参与了 DeepSeek V4 的研发,预览版现已发布!🎉Apr 24
-
很高兴参与了 DeepSeek-V3.2 的研发,现已正式发布,内置面向智能体的推理能力!🎉Dec 01
-
我们的工作 "ROCKET-2" 被 AAAI 2026 接收!Nov 08
-
正式加入 DeepSeek AI,成为一名研究员!🎉Oct 28
-
我们训练出 Minecraft 中首个多任务强化学习智能体 "ROCKET-3",ROCKET 系列就此圆满收官。🎉Aug 01
-
我们发布了 "ROCKET-2" —— 支持跨视角目标指定的 SOTA Minecraft 智能体!Mar 05
-
我们的工作 "ROCKET-1" 被 CVPR 2025 接收!Feb 28
-
我们的工作 "GROOT-2" 被 ICLR 2025 接收!Jan 23

精选论文 (查看全部 )


ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
蔡少斐, 王子豪, 连可为, 牟湛存, 马晓健, 刘安吉, 梁一韬
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
我们提出视觉—时序上下文提示,这是一种 VLM 与策略模型之间的全新通信协议。该协议利用过去观测中的目标分割来引导策略与环境的交互。基于此,我们训练了 ROCKET-1——一个低层策略,它根据拼接的视觉观测与分割掩码预测动作,并由 SAM-2 提供的实时目标跟踪支持。
ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
蔡少斐, 王子豪, 连可为, 牟湛存, 马晓健, 刘安吉, 梁一韬
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
我们提出视觉—时序上下文提示,这是一种 VLM 与策略模型之间的全新通信协议。该协议利用过去观测中的目标分割来引导策略与环境的交互。基于此,我们训练了 ROCKET-1——一个低层策略,它根据拼接的视觉观测与分割掩码预测动作,并由 SAM-2 提供的实时目标跟踪支持。
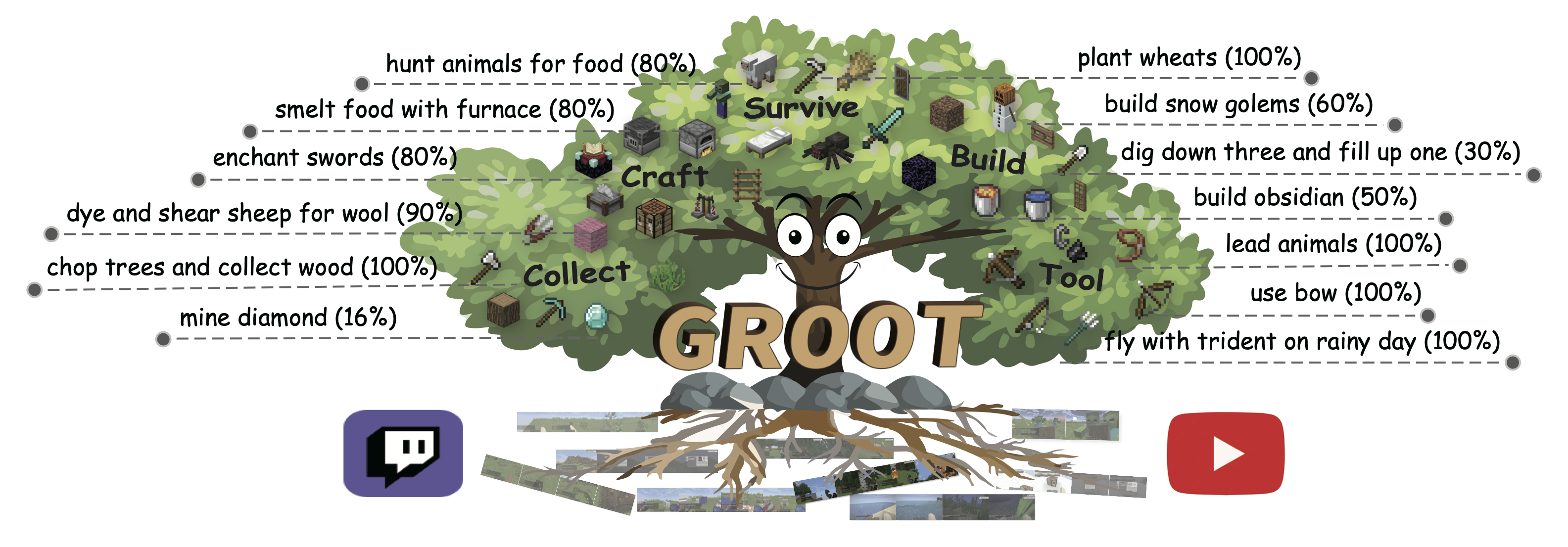
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
本文研究在开放世界环境中构建能够遵循开放式指令的控制器这一问题。我们提出以参考视频作为指令,它既能提供富有表达力的目标设定,又免去了昂贵的文本—游戏过程标注。我们推导出一个全新的学习框架,使其能够从游戏视频中学习这类指令跟随控制器,同时产生一个诱导出结构化目标空间的视频指令编码器。
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
本文研究在开放世界环境中构建能够遵循开放式指令的控制器这一问题。我们提出以参考视频作为指令,它既能提供富有表达力的目标设定,又免去了昂贵的文本—游戏过程标注。我们推导出一个全新的学习框架,使其能够从游戏视频中学习这类指令跟随控制器,同时产生一个诱导出结构化目标空间的视频指令编码器。
Automatic Relation-aware Graph Network Proliferation
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
本文提出自动关系感知图网络增殖(ARGNP),以关系引导的消息传递机制高效搜索图神经网络。具体而言,我们首先设计了一个包含节点与关系学习操作的全新双重关系感知图搜索空间,这些操作能提取层次化的节点/关系信息,并为图上的消息传递提供各向异性的引导。其次,类比细胞增殖,我们设计了一种网络增殖搜索范式,通过迭代执行网络分裂与分化,逐步确定 GNN 架构。
Automatic Relation-aware Graph Network Proliferation
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
本文提出自动关系感知图网络增殖(ARGNP),以关系引导的消息传递机制高效搜索图神经网络。具体而言,我们首先设计了一个包含节点与关系学习操作的全新双重关系感知图搜索空间,这些操作能提取层次化的节点/关系信息,并为图上的消息传递提供各向异性的引导。其次,类比细胞增殖,我们设计了一种网络增殖搜索范式,通过迭代执行网络分裂与分化,逐步确定 GNN 架构。