2025


ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
蔡少斐, 王子豪, 连可为, 牟湛存, 马晓健, 刘安吉, 梁一韬
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
我们提出视觉—时序上下文提示,这是一种 VLM 与策略模型之间的全新通信协议。该协议利用过去观测中的目标分割来引导策略与环境的交互。基于此,我们训练了 ROCKET-1——一个低层策略,它根据拼接的视觉观测与分割掩码预测动作,并由 SAM-2 提供的实时目标跟踪支持。
ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
蔡少斐, 王子豪, 连可为, 牟湛存, 马晓健, 刘安吉, 梁一韬
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'25) 2025
我们提出视觉—时序上下文提示,这是一种 VLM 与策略模型之间的全新通信协议。该协议利用过去观测中的目标分割来引导策略与环境的交互。基于此,我们训练了 ROCKET-1——一个低层策略,它根据拼接的视觉观测与分割掩码预测动作,并由 SAM-2 提供的实时目标跟踪支持。
2024
GROOT-2: Weakly Supervised Multi-Modal Instruction Following Agents
蔡少斐*, 张博为*, 王子豪, 林昊苇, 马晓健, 刘安吉, 梁一韬 (* 共同贡献)
International Conference on Learning Representations (ICLR'25) 2025
我们将该问题构建为半监督学习任务,并提出 GROOT-2——一个多模态可指令智能体,采用一种将弱监督与隐变量模型相结合的全新方法训练。我们的方法包含两个关键部分:受约束的自模仿,利用大量无标注示范使策略学到多样化行为;以及人类意图对齐,利用较少的有标注示范确保隐空间反映人类意图。
GROOT-2: Weakly Supervised Multi-Modal Instruction Following Agents
蔡少斐*, 张博为*, 王子豪, 林昊苇, 马晓健, 刘安吉, 梁一韬 (* 共同贡献)
International Conference on Learning Representations (ICLR'25) 2025
我们将该问题构建为半监督学习任务,并提出 GROOT-2——一个多模态可指令智能体,采用一种将弱监督与隐变量模型相结合的全新方法训练。我们的方法包含两个关键部分:受约束的自模仿,利用大量无标注示范使策略学到多样化行为;以及人类意图对齐,利用较少的有标注示范确保隐空间反映人类意图。
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
王子豪, 蔡少斐, 牟湛存, 林昊苇, Ceyao Zhang, Xuejie Liu, Qing Li, 刘安吉, 马晓健, 梁一韬
Neural Information Processing Systems (NeurIPS'24) 2024
本文提出 OmniJARVIS——一个面向 Minecraft 开放世界指令跟随智能体的全新视觉—语言—动作(VLA)模型。相比此前要么向独立控制器输出文本目标、要么直接产生控制指令的工作,OmniJARVIS 另辟蹊径,通过对多模态交互数据进行统一的 token 化,同时确保强大的推理能力与高效的决策能力。
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents
王子豪, 蔡少斐, 牟湛存, 林昊苇, Ceyao Zhang, Xuejie Liu, Qing Li, 刘安吉, 马晓健, 梁一韬
Neural Information Processing Systems (NeurIPS'24) 2024
本文提出 OmniJARVIS——一个面向 Minecraft 开放世界指令跟随智能体的全新视觉—语言—动作(VLA)模型。相比此前要么向独立控制器输出文本目标、要么直接产生控制指令的工作,OmniJARVIS 另辟蹊径,通过对多模态交互数据进行统一的 token 化,同时确保强大的推理能力与高效的决策能力。
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
王子豪, 蔡少斐, 刘安吉, Yonggang Jin, Jinbing Hou, 张博为, 林昊苇, Zhaofeng He, Zilong Zheng, Yaodong Yang, 马晓健, 梁一韬
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI'24) 2024
本文提出 JARVIS-1——一个开放世界智能体,能够感知多模态输入(视觉观测与人类指令)、生成复杂的规划,并执行具身控制,且全部在广受欢迎而又极具挑战的开放世界 Minecraft 中完成。具体而言,我们在预训练多模态语言模型之上构建 JARVIS-1,将视觉观测与文本指令映射为规划,这些规划最终被分派给目标条件控制器执行。
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
王子豪, 蔡少斐, 刘安吉, Yonggang Jin, Jinbing Hou, 张博为, 林昊苇, Zhaofeng He, Zilong Zheng, Yaodong Yang, 马晓健, 梁一韬
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI'24) 2024
本文提出 JARVIS-1——一个开放世界智能体,能够感知多模态输入(视觉观测与人类指令)、生成复杂的规划,并执行具身控制,且全部在广受欢迎而又极具挑战的开放世界 Minecraft 中完成。具体而言,我们在预训练多模态语言模型之上构建 JARVIS-1,将视觉观测与文本指令映射为规划,这些规划最终被分派给目标条件控制器执行。
2023
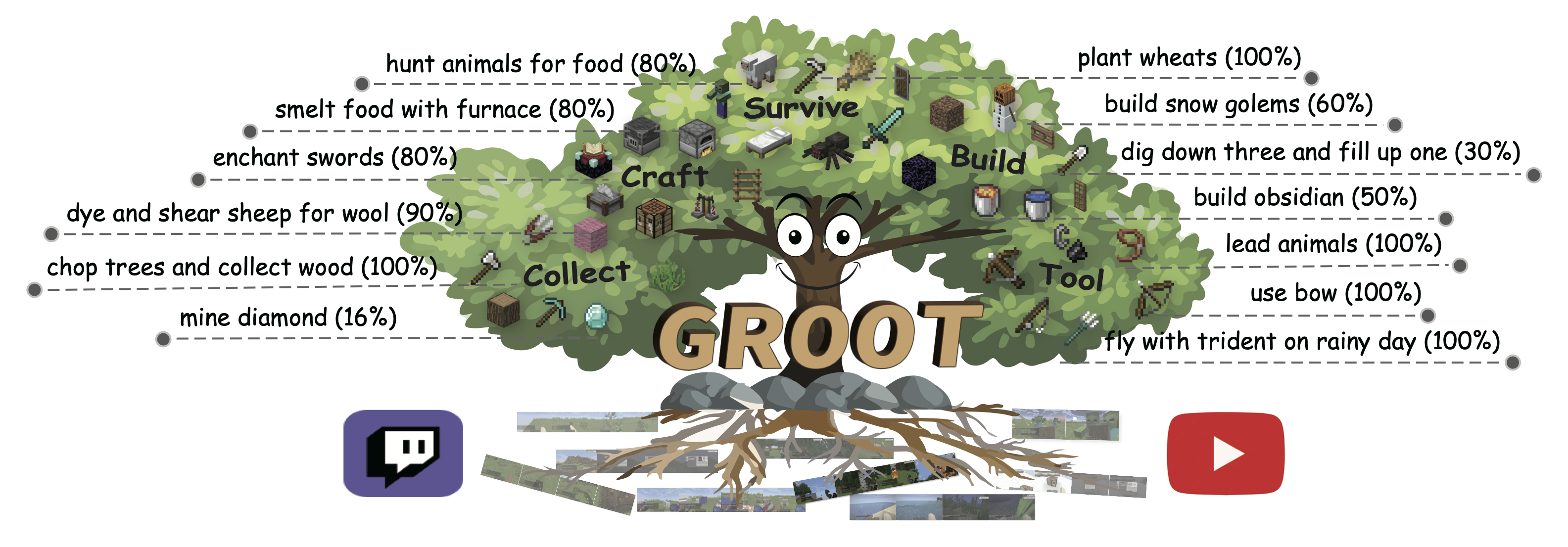
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
本文研究在开放世界环境中构建能够遵循开放式指令的控制器这一问题。我们提出以参考视频作为指令,它既能提供富有表达力的目标设定,又免去了昂贵的文本—游戏过程标注。我们推导出一个全新的学习框架,使其能够从游戏视频中学习这类指令跟随控制器,同时产生一个诱导出结构化目标空间的视频指令编码器。
GROOT: Learning to Follow Instructions by Watching Gameplay Videos
International Conference on Learning Representations (ICLR'24) 2024 Spotlight Top 6.2%
本文研究在开放世界环境中构建能够遵循开放式指令的控制器这一问题。我们提出以参考视频作为指令,它既能提供富有表达力的目标设定,又免去了昂贵的文本—游戏过程标注。我们推导出一个全新的学习框架,使其能够从游戏视频中学习这类指令跟随控制器,同时产生一个诱导出结构化目标空间的视频指令编码器。
DyStyle: Dynamic Neural Network for Multi-Attribute-Conditioned Style Editing
Bingchuan Li*, 蔡少斐*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi (* 共同贡献)
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV'23) 2023
本文提出一种语义与相关性解耦的图卷积方法,通过构建图像专属的图并利用图传播来有效地推理标签。我们引入语义解耦模块,将各类别的语义特征提取为节点;并引入相关性解耦模块,将图像专属的标签相关性提取为边。在该图像专属图上进行图卷积,能更好地挖掘视觉表征较弱的困难标签。
DyStyle: Dynamic Neural Network for Multi-Attribute-Conditioned Style Editing
Bingchuan Li*, 蔡少斐*, Wei Liu, Peng Zhang, Miao Hua, Qian He, Zili Yi (* 共同贡献)
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV'23) 2023
本文提出一种语义与相关性解耦的图卷积方法,通过构建图像专属的图并利用图传播来有效地推理标签。我们引入语义解耦模块,将各类别的语义特征提取为节点;并引入相关性解耦模块,将图像专属的标签相关性提取为边。在该图像专属图上进行图卷积,能更好地挖掘视觉表征较弱的困难标签。
Semantic and Correlation Disentangled Graph Convolutions for Multilabel Image Recognition
蔡少斐, 李亮, 韩歆哲, Shan Huang, Qi Tian, 黄庆明
IEEE Transactions on Neural Networks and Learning Systems (TNNLS'23) 2023
本文提出一种语义与相关性解耦的图卷积方法,通过构建图像专属的图并利用图传播来有效地推理标签。我们引入语义解耦模块,将各类别的语义特征提取为节点;并引入相关性解耦模块,将图像专属的标签相关性提取为边。在该图像专属图上进行图卷积,能更好地挖掘视觉表征较弱的困难标签。
Semantic and Correlation Disentangled Graph Convolutions for Multilabel Image Recognition
蔡少斐, 李亮, 韩歆哲, Shan Huang, Qi Tian, 黄庆明
IEEE Transactions on Neural Networks and Learning Systems (TNNLS'23) 2023
本文提出一种语义与相关性解耦的图卷积方法,通过构建图像专属的图并利用图传播来有效地推理标签。我们引入语义解耦模块,将各类别的语义特征提取为节点;并引入相关性解耦模块,将图像专属的标签相关性提取为边。在该图像专属图上进行图卷积,能更好地挖掘视觉表征较弱的困难标签。
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
Neural Information Processing Systems (NeurIPS'23) 2023
本文指出学习此类策略面临两大挑战:1)由于场景高度多样,任务在状态分布上难以区分;2)部分可观测性导致环境动态具有非平稳性。针对第一个挑战,我们提出目标敏感骨干网络(GSB),促使策略涌现出与目标相关的视觉状态表征;针对第二个挑战,我们进一步引入自适应时域预测模块,帮助缓解学习中的不确定性。
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
Neural Information Processing Systems (NeurIPS'23) 2023
本文指出学习此类策略面临两大挑战:1)由于场景高度多样,任务在状态分布上难以区分;2)部分可观测性导致环境动态具有非平稳性。针对第一个挑战,我们提出目标敏感骨干网络(GSB),促使策略涌现出与目标相关的视觉状态表征;针对第二个挑战,我们进一步引入自适应时域预测模块,帮助缓解学习中的不确定性。
Open-World Multi-Task Control Through Goal-Aware Representation Learning and Adaptive Horizon Prediction
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'23) 2023
本文指出学习此类策略面临两大挑战:1)由于场景高度多样,任务在状态分布上难以区分;2)部分可观测性导致环境动态具有非平稳性。针对第一个挑战,我们提出目标敏感骨干网络(GSB),促使策略涌现出与目标相关的视觉状态表征;针对第二个挑战,我们进一步引入自适应时域预测模块,帮助缓解学习中的不确定性。
Open-World Multi-Task Control Through Goal-Aware Representation Learning and Adaptive Horizon Prediction
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'23) 2023
本文指出学习此类策略面临两大挑战:1)由于场景高度多样,任务在状态分布上难以区分;2)部分可观测性导致环境动态具有非平稳性。针对第一个挑战,我们提出目标敏感骨干网络(GSB),促使策略涌现出与目标相关的视觉状态表征;针对第二个挑战,我们进一步引入自适应时域预测模块,帮助缓解学习中的不确定性。
2022
Automatic Relation-aware Graph Network Proliferation
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
本文提出自动关系感知图网络增殖(ARGNP),以关系引导的消息传递机制高效搜索图神经网络。具体而言,我们首先设计了一个包含节点与关系学习操作的全新双重关系感知图搜索空间,这些操作能提取层次化的节点/关系信息,并为图上的消息传递提供各向异性的引导。其次,类比细胞增殖,我们设计了一种网络增殖搜索范式,通过迭代执行网络分裂与分化,逐步确定 GNN 架构。
Automatic Relation-aware Graph Network Proliferation
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'22) 2022 Oral Top 4.2%
本文提出自动关系感知图网络增殖(ARGNP),以关系引导的消息传递机制高效搜索图神经网络。具体而言,我们首先设计了一个包含节点与关系学习操作的全新双重关系感知图搜索空间,这些操作能提取层次化的节点/关系信息,并为图上的消息传递提供各向异性的引导。其次,类比细胞增殖,我们设计了一种网络增殖搜索范式,通过迭代执行网络分裂与分化,逐步确定 GNN 架构。
2021
Rethinking Graph Neural Architecture Search from Message-Passing
蔡少斐, 李亮, 邓景文, 张北辰, 查正军, 苏荔, 黄庆明
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'21) 2021
本文提出了一种具有全新搜索空间设计的图神经架构搜索(GNAS)方法,能够自动学习在图上具有最优消息传递深度的更优架构。具体而言,我们从消息传递机制出发,设计了具有树形拓扑计算过程的图神经架构范式(GAP),以及特征过滤与邻居聚合两类细粒度原子操作,从而构建出强大的图网络搜索空间。
Rethinking Graph Neural Architecture Search from Message-Passing
蔡少斐, 李亮, 邓景文, 张北辰, 查正军, 苏荔, 黄庆明
IEEE/CVF Computer Vision and Pattern Recognition (CVPR'21) 2021
本文提出了一种具有全新搜索空间设计的图神经架构搜索(GNAS)方法,能够自动学习在图上具有最优消息传递深度的更优架构。具体而言,我们从消息传递机制出发,设计了具有树形拓扑计算过程的图神经架构范式(GAP),以及特征过滤与邻居聚合两类细粒度原子操作,从而构建出强大的图网络搜索空间。
2020
IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning
Zhenhuan Liu, 邓景文, 李亮, 蔡少斐, Qianqian Xu, Shuhui Wang, 黄庆明
ACM International Conference on Multimedia (MM'20) 2020 Oral
传统的条件图像生成模型主要关注生成高质量、视觉逼真的图像,却难以解决图像与指令之间的局部一致性问题。为此,我们提出增量推理生成对抗网络(IR-GAN),旨在推理图像中的视觉增量与指令中的语义增量之间的一致性。
IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning
Zhenhuan Liu, 邓景文, 李亮, 蔡少斐, Qianqian Xu, Shuhui Wang, 黄庆明
ACM International Conference on Multimedia (MM'20) 2020 Oral
传统的条件图像生成模型主要关注生成高质量、视觉逼真的图像,却难以解决图像与指令之间的局部一致性问题。为此,我们提出增量推理生成对抗网络(IR-GAN),旨在推理图像中的视觉增量与指令中的语义增量之间的一致性。